


宁波政企机房,金融级骨干网,优质高端体验、100%性能释放、配备金盾防火墙,可提交工单免费申请ipv6.





在这个信息爆炸的时代,寻找免费且合法的影视资源成为了众多电影爱好者的共同需求。虽然市场的影视平台众多,但并非所有内容都免费,用户经常需要为高清视频或最新上映的电影付费。然而,借助Python这一强大的编程工具,我们可以在合法合规的前提下,探索一些更为灵活的方式来获取并观看电影,这主要通过自动化脚本从合法、免费的影视资源网站中提取链接或信息来实现,并非鼓励盗版或不正当途径。
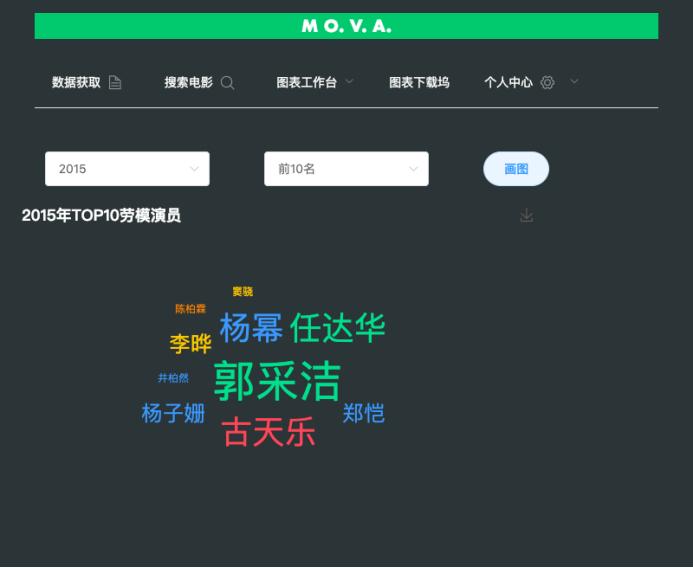
在深入讨论技术细节之前,必须强调任何技术手段都应遵守版权法律和互联网使用政策。本篇文章旨在分享如何利用Python技术实现合法范围内的影视信息检索与自动播放管理,而不是教你如何侵犯版权或者绕过付费机制。

网络爬虫: 通过编写Python脚本使用requests和BeautifulSoup库,可以从公开的影视论坛、信息网站或是官方提供的免费资源列表中抓取电影名称、简介以及可观看地址。例如,分析特定网站上的HTML结构,提取出免费电影节目的链接。
API调用: 有些合法的平台提供了API接口,允许开发者查询其公开的影视资源目录。利用requests库发起HTTP请求,获取JSON格式的数据后,用户可以根据返回的信息选择想看的影片,并跳转至相应播放页面。
自动化浏览器操作: 对于那些没有提供API,但允许用户自由浏览和点击观看的网站,可以使用Selenium等工具模拟浏览器行为,自动打开网页、搜索电影并点击播放。
假设你想从一个合法的、提供免费老电影资源库中检索特定影片的信息,下面是一个简化的代码框架:
import requests
from bs4 import BeautifulSoup
def fetch_movie_info(url):
# 发送HTTP请求获取网页内容
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
# 假设电影信息包含在特定的div标签内,通过CSS选择器获取
movies = soup.select('.movie-item')
for movie in movies:
title = movie.select_one('.title').text.strip()
# 这里可以添加更多信息的获取逻辑,如导演、年份等
print(f"电影名: {title}")
# 使用示例
fetch_movie_info('http://example-free-movies-site.com/movies')使用Python进行影视信息的自动化获取确实打开了技术爱好者的一片新天地,其核心价值在于提升信息检索效率与智能化用户体验,而非取代正版购买行为。合理的应用场景包括搭建个人影视库管理系统、创建推荐算法辅助选择观影清单等,所有操作均应基于尊重版权的基础之上。
务必谨记,技术的力量在于创造价值,而非用之不当。作为一个负责任的开发者或用户,我们应该利用技术来促进合法内容的获取与分享,同时遵守知识产权法律法规,维护良好的网络环境。
Linux工具推荐:
支持一键换源/安装宝塔/1p/系统优化等,运维好帮手!Github开源工具,欢迎star~
https://cb2.cn/helpcontent/230.html
(开源地址:https://github.com/JiaP/cb2cn)
---------------------------------------
邀请好友注册购买可获得高额佣金!


















